


History, operation and fields of application of the Large Language Model (LLM)

Large Language Model (LLM): Artificial Intelligence systems capable of understanding and generating text in a human-like manner. Unlike traditional software that follows programmed rules, LLMs learn autonomously by analyzing billions of pages of text.
ChatGPT, the most well-known face of this technology, is just the tip of the iceberg: behind the conversational interface lies a revolution that is transforming the way we interact with computers.
HISTORY
Language models originated in the 1980s with systems that predicted the next word using simple probability calculations.
The first real leap came in 2013 with Google‘s Word2Vec, which represents words as mathematical vectors capable of capturing meaning relationships.
The true revolution exploded in June 2017 with the publication of the paper “Attention Is All You Need” by Google researchers. This work introduced the transformer architecture, which eliminated old sequential systems, replacing them with parallel attention mechanisms. The crucial advantage: instead of reading text word by word, transformers analyze entire sentences simultaneously.
In 2018-2020, the first large models arrived.
Google launched BERT with 340 million parameters, excellent for understanding language, while OpenAI developed GPT, focused on text generation. GPT-3, launched in 2020 with 175 billion parameters, demonstrated that larger models develop unexpected capabilities.
November 2022 marked the mainstream turning point: ChatGPT reached 100 million users in two months. In 2023-2024, GPT-4 introduced multimodal capabilities, Google responded with Gemini, while Meta released Llama for free. Context windows exploded from 2,000 to 10 million words, allowing the analysis of entire books.
FUNCTIONALITY
The operation of LLMs is surprisingly simple: predict the next word. It chooses a word, adds it, and repeats. It doesn’t know the answer in advance but builds the sentence word by word.
The transformer architecture is the heart of the system. Unlike smartphone autocomplete, which only looks at the last few words, transformers analyze the entire context through the self-attention mechanism. In the sentence “The animal didn’t cross the street because it was too tired,” attention connects “it” with “animal” rather than “street,” resolving the ambiguity.
Parameters are the model’s memory, where billions of numerical values are adjusted during training. GPT-3 has 175 billion; GPT-4 exceeds a trillion.
Training occurs in two phases: first, the model reads billions of web pages, books, and articles to learn the structure of language, and subsequently, it is fine-tuned with high-quality examples to transform it into a useful assistant.
The context window represents the “working memory,” meaning how much text the model can consider simultaneously. The latter has grown from about 1,500 words in 2020 to over 750 pages in 2024.

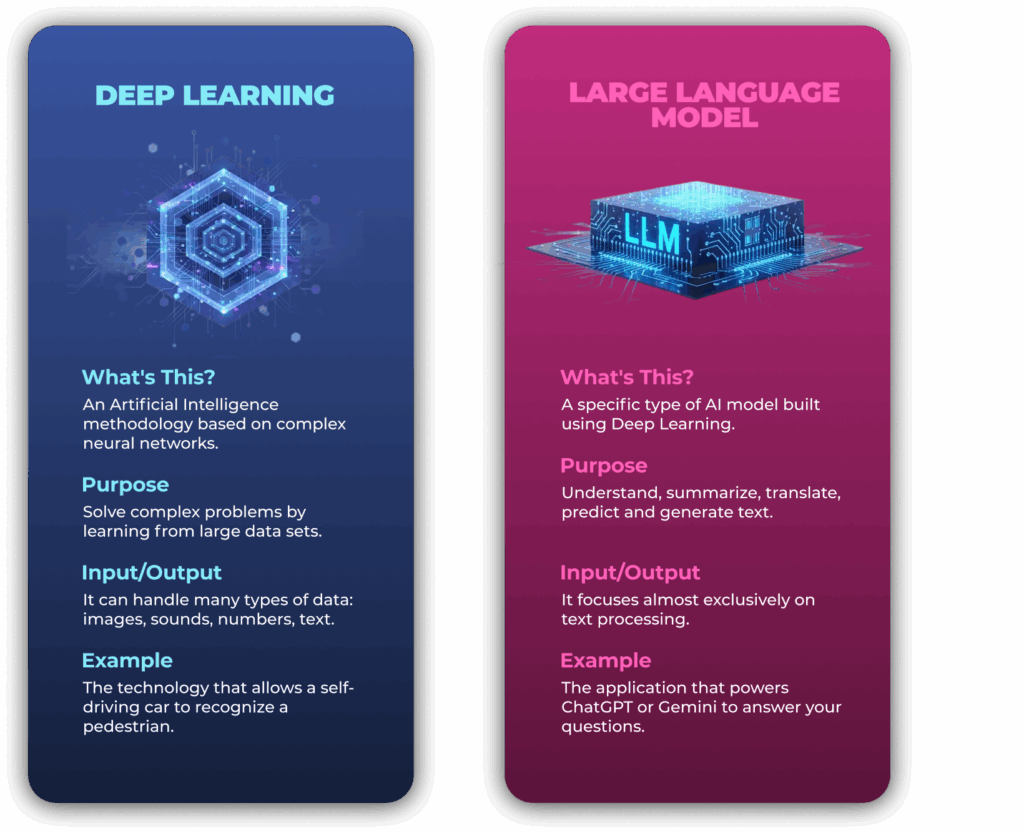
MACHINE LEARNING AND DEEP LEARNING
LLMs are the pinnacle of a technological evolution.
Traditional Machine Learning works with structured data in tables but requires experts to manually specify which features to look for. It is perfect for predicting prices or loan approvals; it is less specialized in images and free text.
Deep Learning introduces neural networks that automatically learn the relevant features. It excels with unstructured data but requires enormous datasets and powerful GPUs.
LLMs are a specialized application of Deep Learning focused on language. The hierarchy starts with Artificial Intelligence, Machine Learning, Deep Learning, and finally concerns Large Language Models. Each stage builds on the previous one, making increasing levels of sophistication possible.
FIELDS OF APPLICATION
LLMs are transforming various sectors.
In customer service they offer continuous assistance, in programming they accelerate software development with GitHub Copilot and in education they provide personalized tutors. Companies report gains of 30-45% in content creation, and multilingual translation has reached unprecedented quality.
Despite the numerous application fields for LLMs, there are structural limits that create obstacles in their use. Hallucinations represent the main problem, as LLMs generate false information with convincing confidence.
Furthermore, the environmental cost is considerable. Training GPT-3 emitted carbon equivalent to 550 New York-San Francisco flights. Every ChatGPT query uses 15 times more energy than a Google search, and with a billion daily interactions, the impact grows rapidly.
LLMs excel as assistants for writing, summarizing documents, data analysis, and translation, but they require human supervision in critical applications like medical diagnoses, legal advice, and financial decisions.
For these reasons, an augmentation approach is recommended: LLMs should be used as tools that amplify human capabilities, without replacing judgment and responsibility.


